你能获得的对程序最大的加速比就是当你第一次让它工作起来的时候。
在讲解如何优化程序性能之前,我们首先要明确写程序最主要的目标就是使它在所有可能的情况下都能正常工作,一个运行的很快的程序但是却是错误的结果是没有任何用处的,所以我们在进行程序性能优化之前,首先要保证程序能正常运行,且结果是我们需要的。
而且在很多情况下,让程序跑的更快是我们必须要解决的问题。比如一个程序要实时处理视频帧或者网络包,那么一个运行的很慢的程序就不能解决此问题。再比如一个计算任务计算量非常大,需要数日或者数周,如果我们哪怕只是让它运行的快20%也会产生重大影响。
1、编写高效程序的切入点
①、选择一组合适的算法和数据结构。
②、编写出编译器能够有效优化以转换成高效可执行的源代码。
③、多线程并行处理运算。
对于第一点,程序=数据结构+算法,选择合适的数据结构和算法无疑对于提高程序的运行效率有很大的影响。第二点对于编程者则需要理解编译器的优化能力以及局限性,编写程序看上去只是一点小小的改动,可能都会引起编译器优化方式很大的变化;第三点技术主要这对运算量特别大的运算,我们将一个大的任务分成多个小任务,这些任务又可以在多核和多处理器的某种组合上并行的计算,这里我们也需要知道,即使是利用并行性,每个并行的线程都要以最高性能的方式执行。
2、编译器的优化能力和局限性
正确性,正确性,正确性!!!这个要着重提醒,所以编译器必须很小心的对程序使用安全的优化。限制编译器只进行安全的优化,会消除一些造成错误的运行结果,但是这也意味着程序员必须花费更大的力气写出程序使编译器能够将之转换为有效机器代码。
对于下面两个程序:
void add1(int *xp,int *yp){ *xp += *yp; *xp += *yp; }
void add2(int *xp,int *yp){ *xp += 2* *yp;} 对上上面两个函数add1和add2,它们都是将存储在由指针 yp 指示的位置处的值两次加到指针 xp 指示的位置处的值。但是明显add2的执行效率要高,它只要求 3 次存储器的引用(读*xp,读*yp,写*xp),而add1需要 6 次存储器引用(2次读*xp,2次读*yp,2次写*xp)。
下面有评论指出乘法指令要比加法指令慢很多,这里的add1是两次加法指令,而add2是一次乘法指令,按道理来讲是add1要比add2快,但我这里为什么说add2要快呢?我们可以看一下汇编级别的代码:
我们通过执行 gcc -O0 -S add1.c 优化级别为0,生成汇编代码:
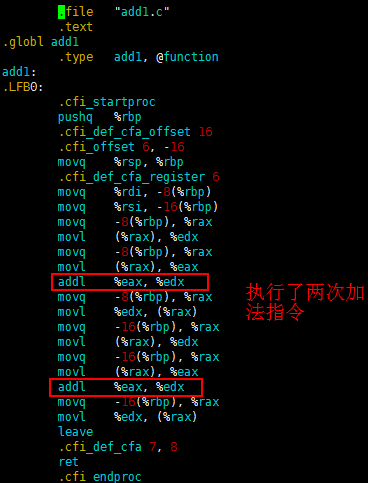
同理通过执行 gcc -O0 -S add2.c 优化级别为0,生成汇编代码:
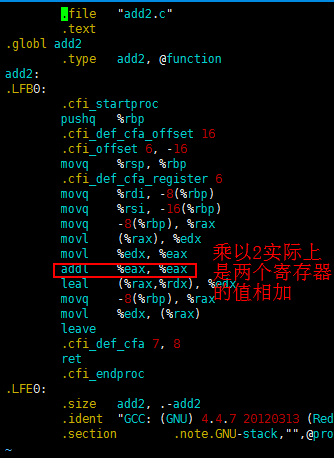
很明显,add2的乘法指令被转换成一次加法指令了,虽然乘法指令确实比加法指令慢。但是要注意这里是乘以2,如果倍数大于2,那就不一定了。
因此,如果编译器要优化add1,我们可以认为add2是其优化后的代码。但实际上真的是这样吗?如果 xp 等于 yp,那么变成如下:
void add1(int *xp,int *xp){ *xp += *xp; *xp += *xp; }
void add2(int *xp,int *xp){ *xp += 2* *xp;} 我们可以看到,这个时候对于 add1,xp的值会增加 4 倍,但是 add2 当中,xp 的值只增加 3 倍。由于编译器不知道参数 xp 和 yp 是否相等,它必须假定他们有可能相等,所以不会产生 add2 作为 add1 的优化版本。
在各种编译器中,我们前面说过的 gcc 编译器,可以通过加参数O0 -->> O1 -->> O2 -->> O3,分别是从没有优化到优化级别最高。但是基本上编译器都不会对程序进行各种激进的优化,所以程序员必须以一种简化编译器生成高效代码的任务来编写程序。如何编写,请接着往下面看。
3、程序的性能表示
处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹(GHz),即十亿周期每秒来表示。例如,当表明一个系统有“4GHz”处理器,这表示处理器时钟运行频率为 4*109 千兆赫兹。每个时钟周期的时间是时钟频率的倒数。通常用纳秒(nanosecond,1 纳秒等于10-9秒),或者皮秒(picosecond,1 皮秒等于10-12秒)来表示,一个 4GHz 的十周周期为0.25纳秒,或者说250皮秒。从程序员的角度来看,用时钟周期来表示度量标准要比用纳秒或者皮秒来表示有用的多。
用时钟周期来表示,度量值表示的是执行了多少条指令,而不是时钟运行的有多快。
4、提高程序的性能方法
这本书的作者讲解如何优化程序性能主要从两个方面入手,第一个是与机器无关,第二个是与机器相关。
与机器无关:
①、消除循环的低效率:将每次循环中执行多次但计算结果不改变的部分提出循环,这样只需计算一次,而不用循环一次,计算一次。以此提高算法效率。
②、减少过程调用:也就是减少函数方法的调用,因为函数方法的调用会带来相当大的开销。但是这样也会带来一个缺点,就是破坏程序的模块化,所以我们需要权衡利弊。
③、消除不必要的存储器引用:在循环中不停地对指针所指向的变量赋值的时候,我们可以用一个中间变量代替指针,以增加速度。
④、选择合适的算法和数据结构:为遇到的问题选择合适的算法和数据结构,避免使用产生糟糕性能的算法或编码技术。
与机器相关:
①、理解现代处理器
在代码级上,看上去似乎是一次执行条指令,每条指令都从寄存器或存储器中取值,执行一个操作后,并把结果存到一个寄存器或存储器位置。但是实际上,在处理器中是同时对多条指令求值,称为指令级并行。现代微处理器了不起的成就就是它们采用复杂而奇异的微处理结构,多条指令可以并行执行,同时又呈现出一种简单的顺序执行指令的表象。
当一系列操作必须按照严格的顺序执行时,就会遇到延迟界限,因为在下一条指令开始之前,这条指令必须结束。当代码中的数据相关限制令处理器利用指令级并行的能力时,延迟界限能够限定程序性能。吞吐量界限刻画了处理器功能单元的原始计算能力。这个界限是程序性能的终极限制。
下图是一个现代微处理器的简化示意图:
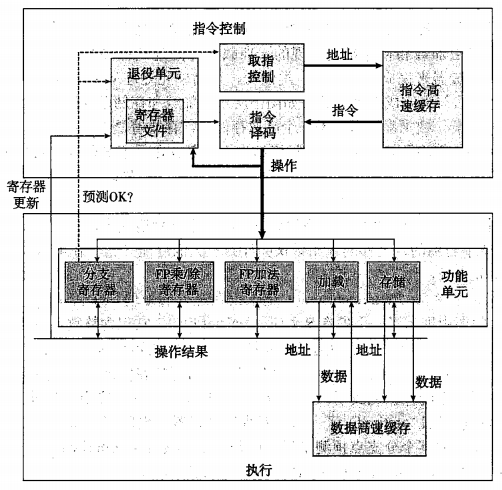
指令控制单元(Instruction Control Unit,ICU)从指令高速缓存(instruction cache)中读取指令,并产生一系列基本操作。指令高速缓存是一个特殊的高速缓存存储器,它存储最近访问的指令。通常ICU会在当前正在执行的指令很早之前取指,这样它才有足够的时间对指令译码,并把操作发给执行单元 EU(Execution Unit ,EU),然后由EU完成ICU产生的基本操作。
②、提高并行性
循环分割,利用功能单元的流水线化的能力提高代码性能。对于一个可结合和可交换的合并操作来说,比如说整数加法和乘法,我们可以通过将一组合并操作分割成两个或更多的部分,通过在最后合并结果来提高性能。